


L’Architecture Fédérée : Le Protocole en Cinq Étapes
L’entraînement fédéré suit un protocole de communication strict entre le serveur central (qui maintient le modèle global) et les clients (les appareils périphériques). Ce protocole est un cycle continu de communication et de calcul qui définit l’architecture du FL :
Sélection Stochastique des Clients (Sampling)
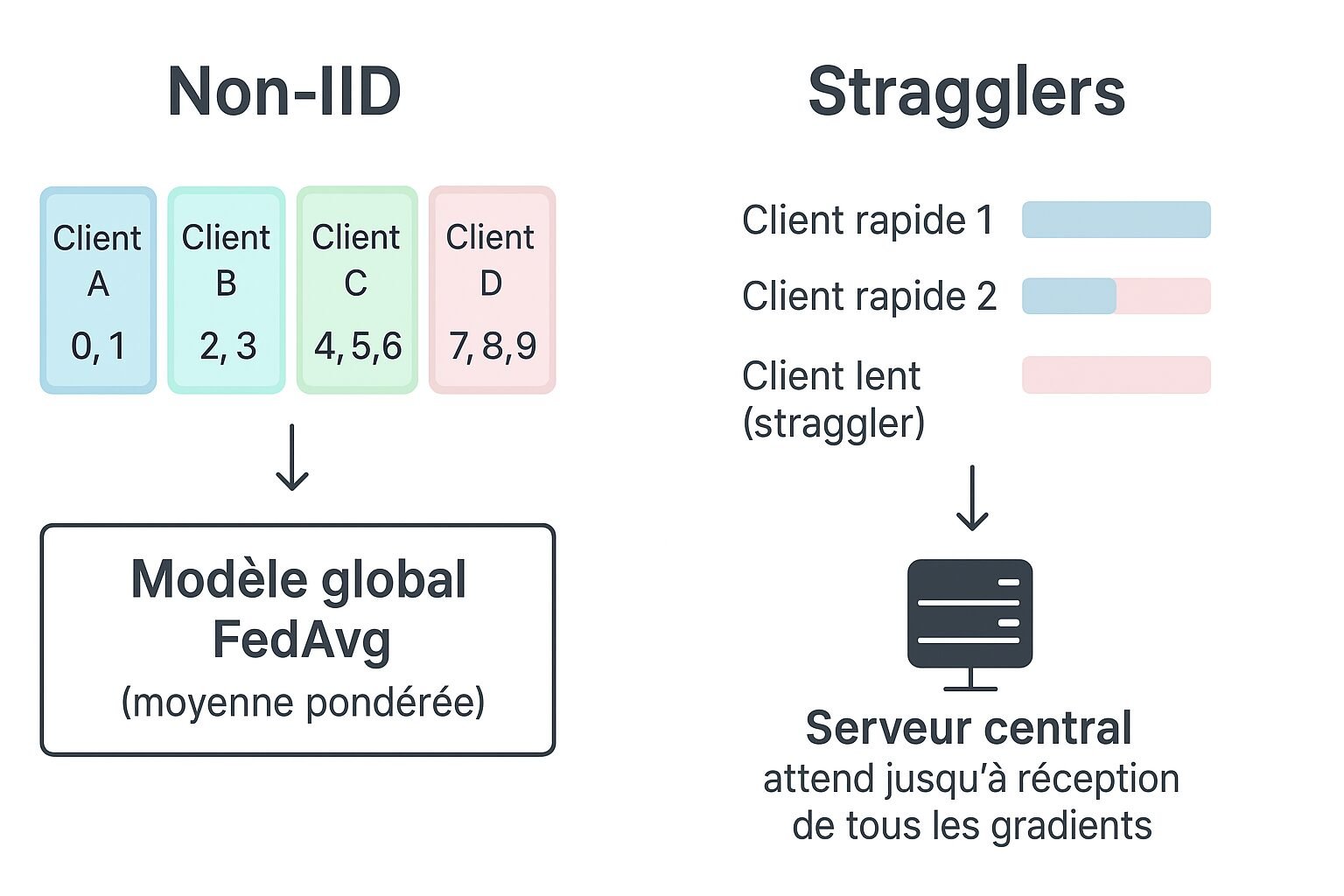
À chaque cycle d’entraînement (ou round), le serveur sélectionne aléatoirement un petit sous-ensemble d’appareils actifs (clients) pour participer. Cette sélection est souvent basée sur des critères de disponibilité (appareil connecté au Wi-Fi, niveau de batterie suffisant).
“Broadcast” du Modèle Global
Le serveur envoie une copie de l’état actuel du modèle global () à tous les clients sélectionnés. Le modèle est léger car il s’agit uniquement des poids et des biais.
Entraînement Local et Descente de Gradient
Chaque client entraîne le modèle global sur son propre jeu de données local (). Il effectue une descente de gradient, apprenant des caractéristiques spécifiques à ses données.
Le client génère ainsi une mise à jour locale (). C’est l’étape de calcul qui protège la donnée brute.
Envoi des Mises à Jour (Gradients)
Les clients renvoient leurs mises à jour () – et non les données brutes – au serveur central. Ces mises à jour sont généralement chiffrées ou obscurcies pour ne pas divulguer d’information sensible par inversion de gradient.
Agrégation Sécurisée (Federated Averaging – FedAvg)
Le serveur agrège toutes les mises à jour locales reçues. L’algorithme Federated Averaging (FedAvg) est la méthode la plus courante : il calcule une moyenne pondérée des mises à jour pour créer la nouvelle version du modèle global ().
Le poids de chaque mise à jour est souvent proportionnel à la quantité de données d’entraînement utilisées par le client.
où nk est la taille du jeu de données du client k,
n la taille totale,
ΔWk la mise à jour locale.
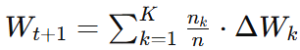
Le modèle global mis à jour est prêt pour le cycle suivant.
Sécurité et Confidentialité – Le Complément FHE
Bien que le FL soit conçu pour la confidentialité, il n’est pas infaillible. Le fait de ne pas envoyer la donnée brute est une énorme avancée, mais cela ne protège pas contre l’extraction d’informations sensibles à partir des mises à jour du modèle (les gradients) envoyées au serveur.
Le développeur doit donc mettre en place des défenses cryptographiques et statistiques supplémentaires.
L’Attaque par Inversion de Gradient
Le maillon faible du FL réside dans l’étape 4, lorsque les clients envoient leurs mises à jour (). Les recherches ont montré qu’un attaquant interne (un administrateur du serveur central) peut utiliser ces gradients pour reconstruire ou inférer des informations sur les données d’entraînement originales du client. C’est l’Attaque par Inversion de Gradient.
C’est pourquoi le FL, seul, n’est pas suffisant pour une confidentialité absolue.
La Protection Statistique : La Confidentialité Différentielle (Differential Privacy – DP)
Pour contrer l’inversion de gradient, la solution la plus courante est la Confidentialité Différentielle (DP).
Le DP fonctionne en ajoutant une quantité contrôlée de bruit aléatoire aux mises à jour du modèle avant qu’elles ne soient renvoyées au serveur central.
Effet
L’ajout de bruit masque les contributions exactes d’une seule donnée utilisateur. Si l’on ajoute ou retire un utilisateur de l’ensemble de données, le changement dans le gradient est statistiquement négligeable. Cela garantit qu’aucune donnée d’un client spécifique ne peut être déduite.
Compromis
Le DP garantit la confidentialité, mais la quantité de bruit ajoutée a un coût sur la précision finale du modèle. L’ingénieur doit trouver le bon équilibre entre la garantie de confidentialité (le paramètre ) et la performance du modèle.
Le Complément Cryptographique : FHE et PQC pour l’Agrégation
Comme détaillé dans notre article précédent sur le FHE, ce chiffrement permet d’agréger des données chiffrées sans jamais révéler leur contenu. Ici, il s’applique directement aux gradients envoyés par les clients.
La dernière faille se situe à l’étape 5, l’Agrégation Moyenne (FedAvg). Que se passe-t-il si le serveur central est compromis et qu’il reçoit des gradients (même bruités par DP) de tous les clients ?
Le FHE intervient ici comme un complément parfait :
Rôle du FHE
Au lieu d’envoyer les gradients en clair, les clients utilisent le FHE pour chiffrer leurs mises à jour avant l’envoi. Le serveur central peut effectuer l’opération de moyenne directement sur les gradients chiffrés, éliminant le risque d’attaque interne lors de l’agrégation.

Garantie PQC
Enfin, pour une sécurité pérenne, il est essentiel que les mécanismes de chiffrement utilisés par le FL et le FHE soient basés sur des schémas Post-Quantiques (comme le RLWE mentionné dans votre article sur le FHE). C’est la seule façon de garantir que la confidentialité assurée aujourd’hui ne sera pas déchiffrée dans dix ans. Pour une exploration approfondie de ce risque, consultez notre article sur la Cryptographie Post-Quantique.